To begin with any machine learning project, you need data. MILO-ML works with numerical data to build binary classification predictive analytics models. If your data is in an Excel file, you can quickly get started in MILO-ML. Within your Excel sheet, the rows indicate cases (e.g. each row would be the data from that individual) and columns represent the features/variables data points while the last column represents your target of interest.
See documentation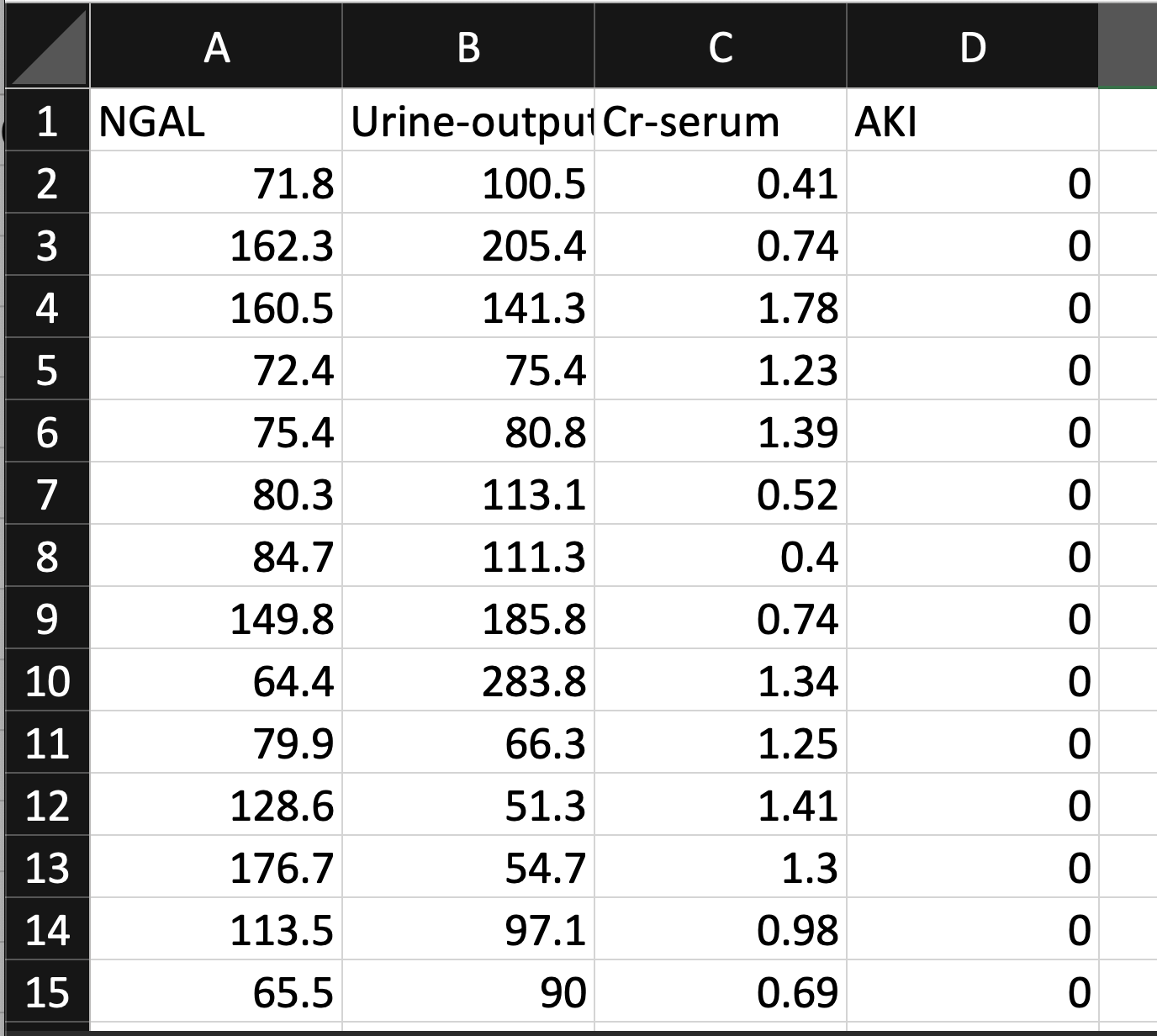
Once your data is prepared for MILO-ML, you can upload it using our easy user interface
See documentation
After upload, you can view some basic insights about your data and ensure the study is valid before proceeding.
See documentation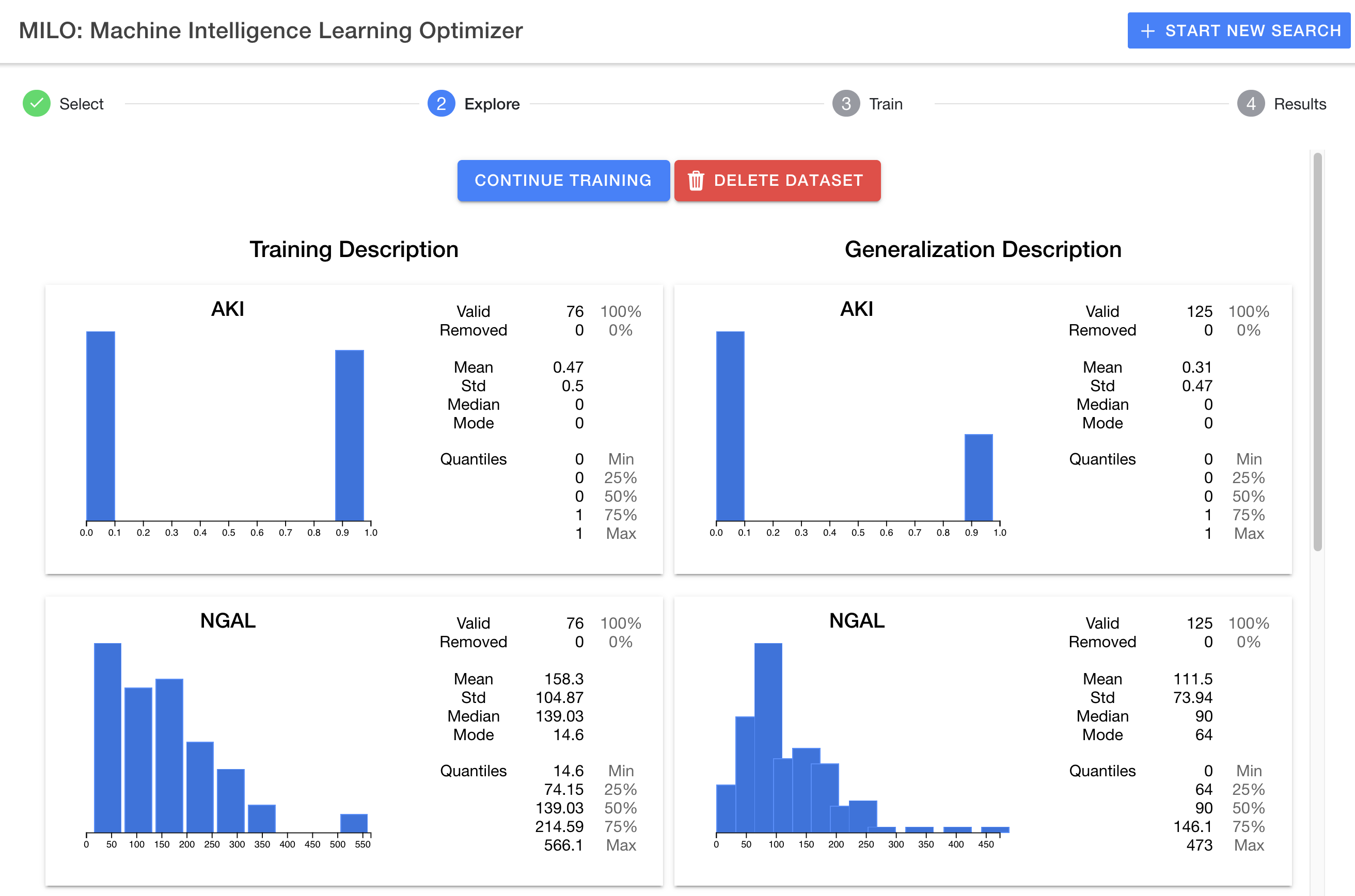
After completing data validation, MILO-ML prepares to train your models by selecting various pipeline elements that ultimately generate thousands of ML models.
See documentation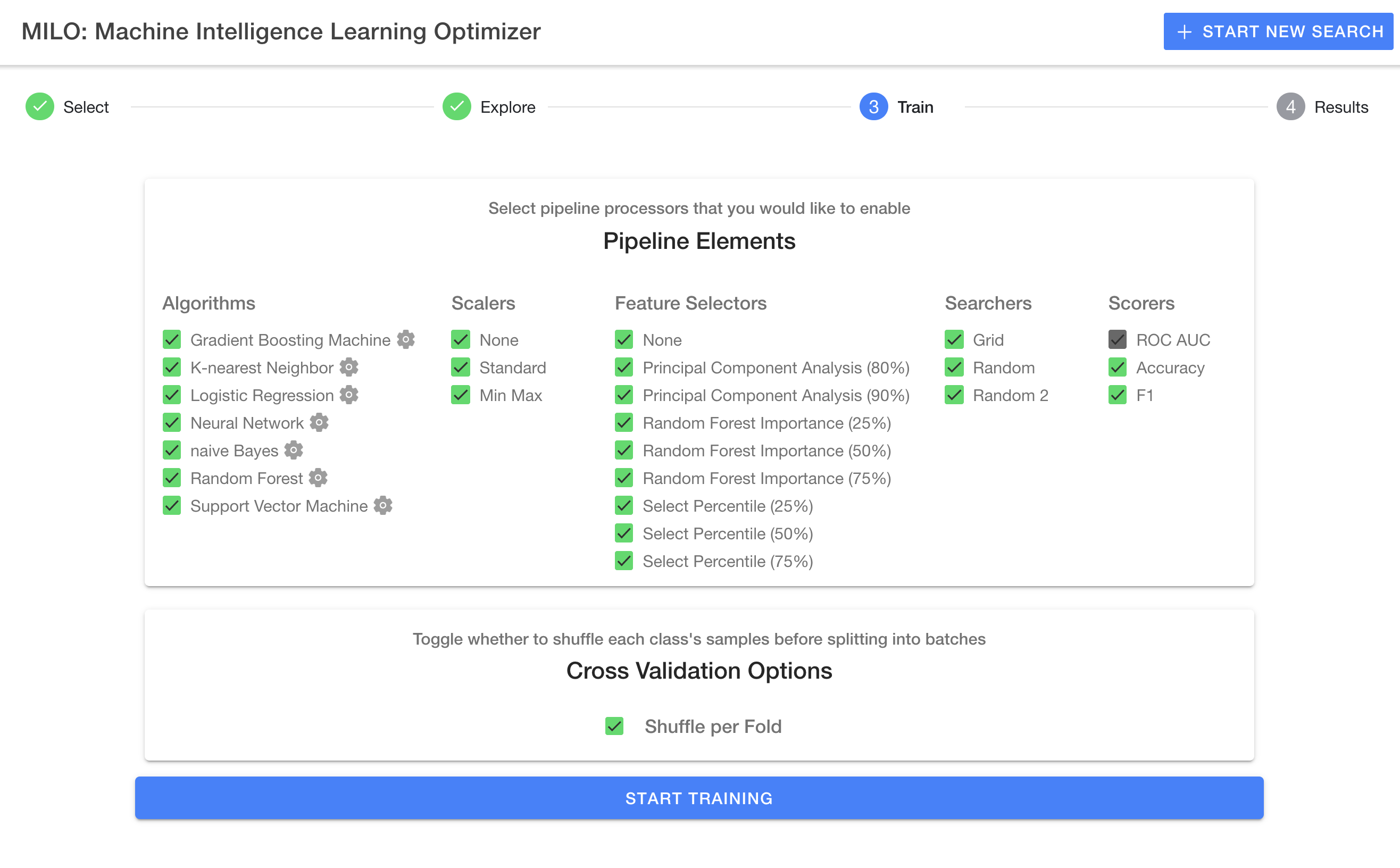
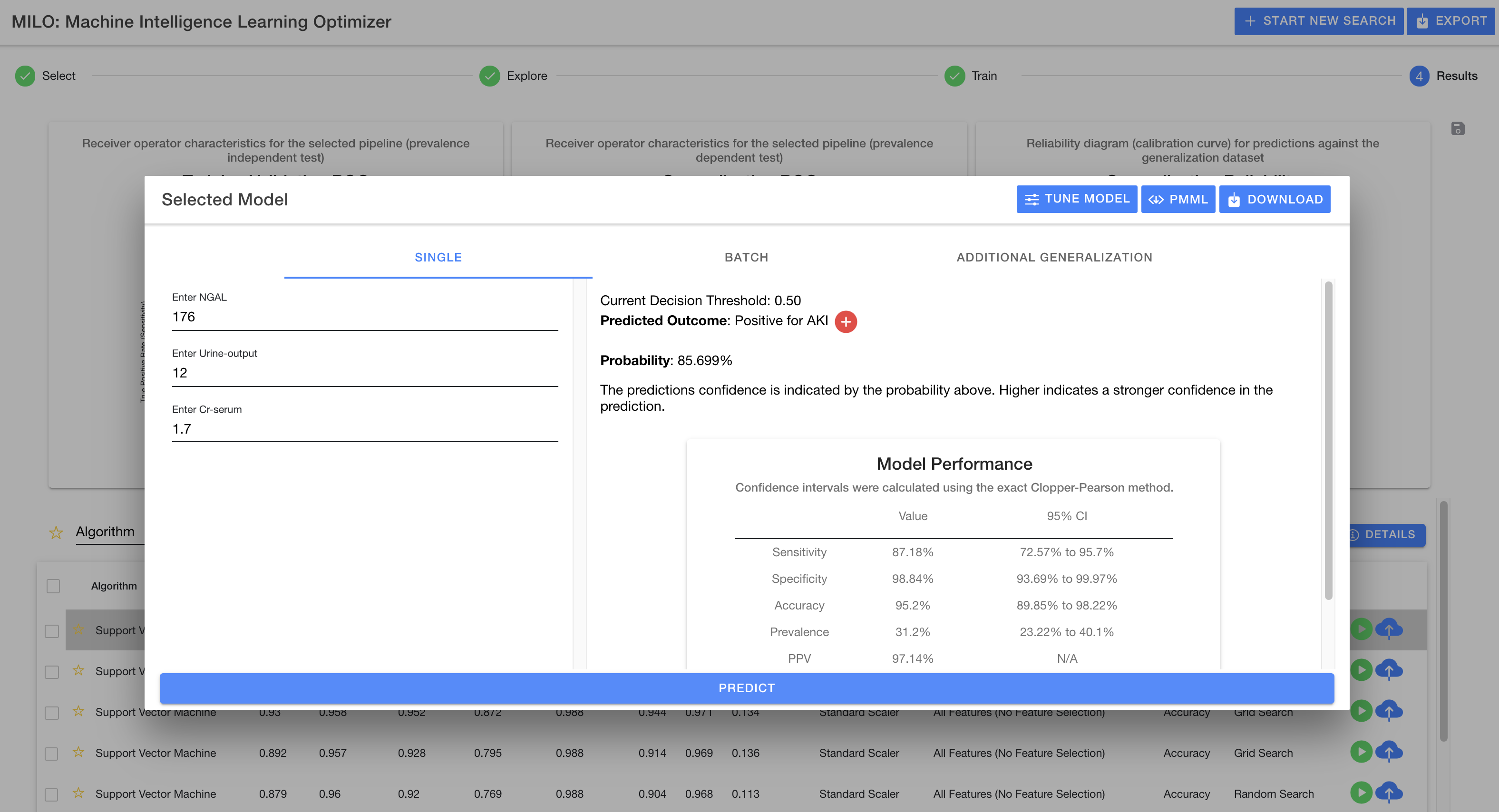
After MILO-ML completes building the ML models, you will be presented with results showing all the various models MILO-ML identified with their performance against the second generalization test set which minimizes overfitted models.
See documentation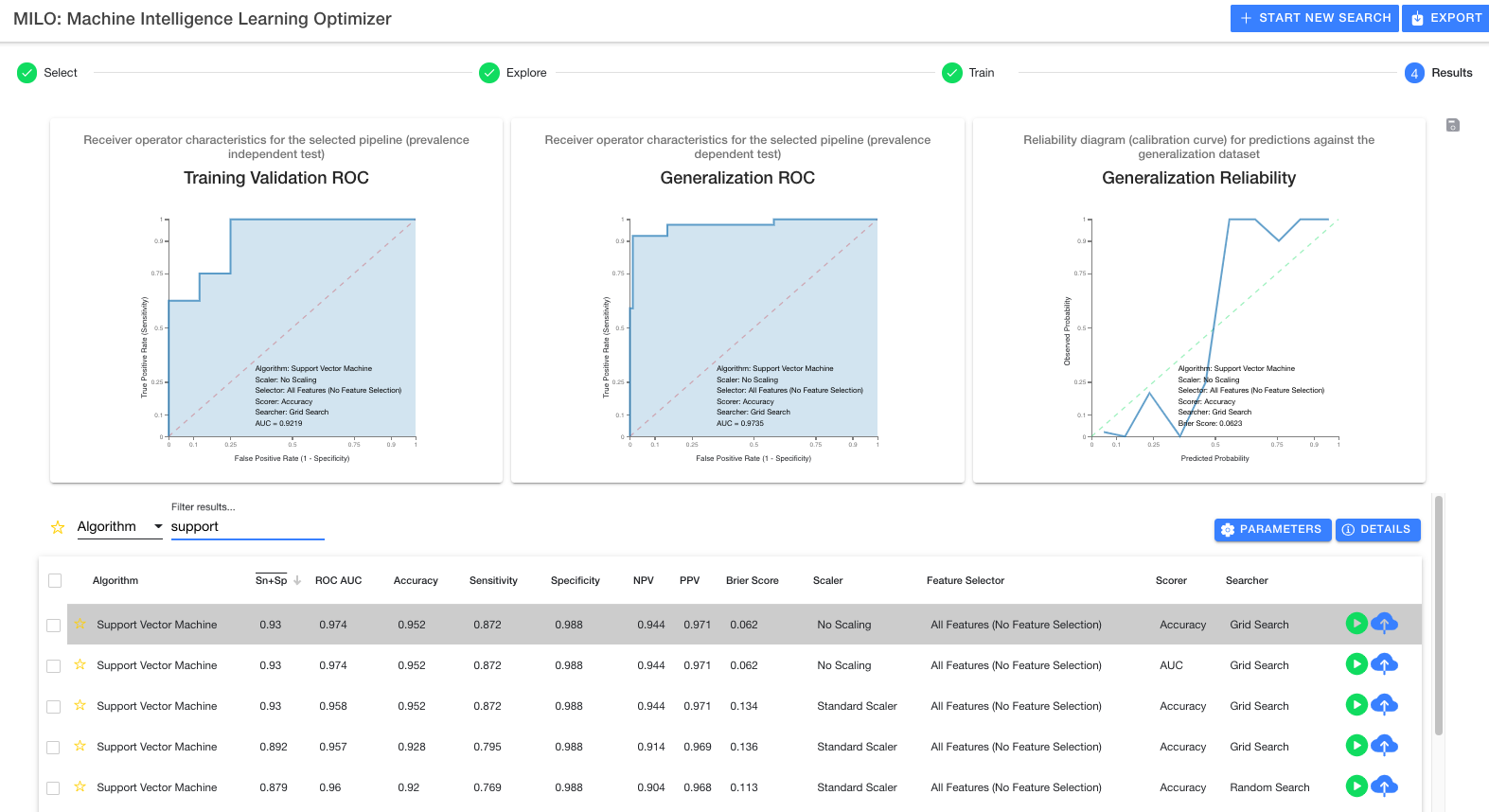
The best performing model can then be published to make new predictions on future data
See documentation