# Train and Test Builder
Splits a single data file into two separate data files.
In order for a dataset to be used in MILO, the data needs to be separated into a training / initial validation test file (from here on referred to as "Training Data") and a follow up "Generalization testing data". While this can be done independently, MILO offers a Train Test Split tool which allows you to quickly segment your data. This is how it works:
Navigate to the Preprocessing Tools from the MILO home page and then select Train and Test Builder.
Start by selecting the single dataset of interest by clicking on the Single Data File icon or input box.
TIP
This single data file must be in the form of a CSV file format, a “save as” option within excel or other database tools
Choose your file from the folder of interest (example below reflects MacOS folder system).
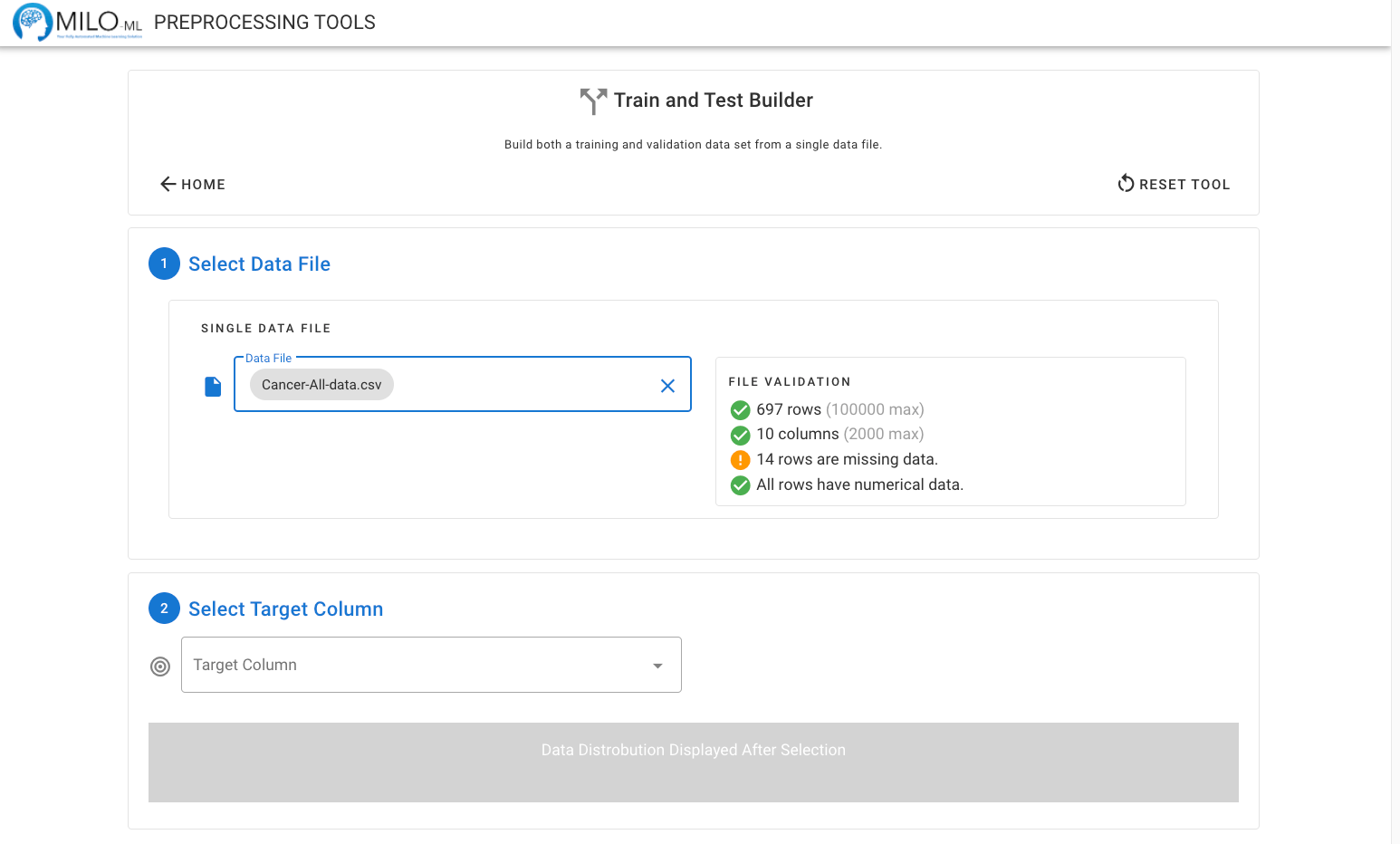
Once uploaded, the CSV file is automatically validated for use within MILO. If any rows are missing data, these will be identified and subsequently removed in later steps. The data is also checked to ensure all columns are compatible with MILO’s requirement for numerical data. As Step 2, the target (outcome) column needs to be selected with the dropdown. Column names are generally sorted from last (target column) to first (independent variables / features), so the final column (i.e. target) will be displayed first for your convenience.
Once the target column has been selected, the prevalence of the two classes will be calculated and displayed. If any rows are excluded because they are missing data from specific columns, the adjusted number of rows in each of the classes will be displayed as well (as seen below).
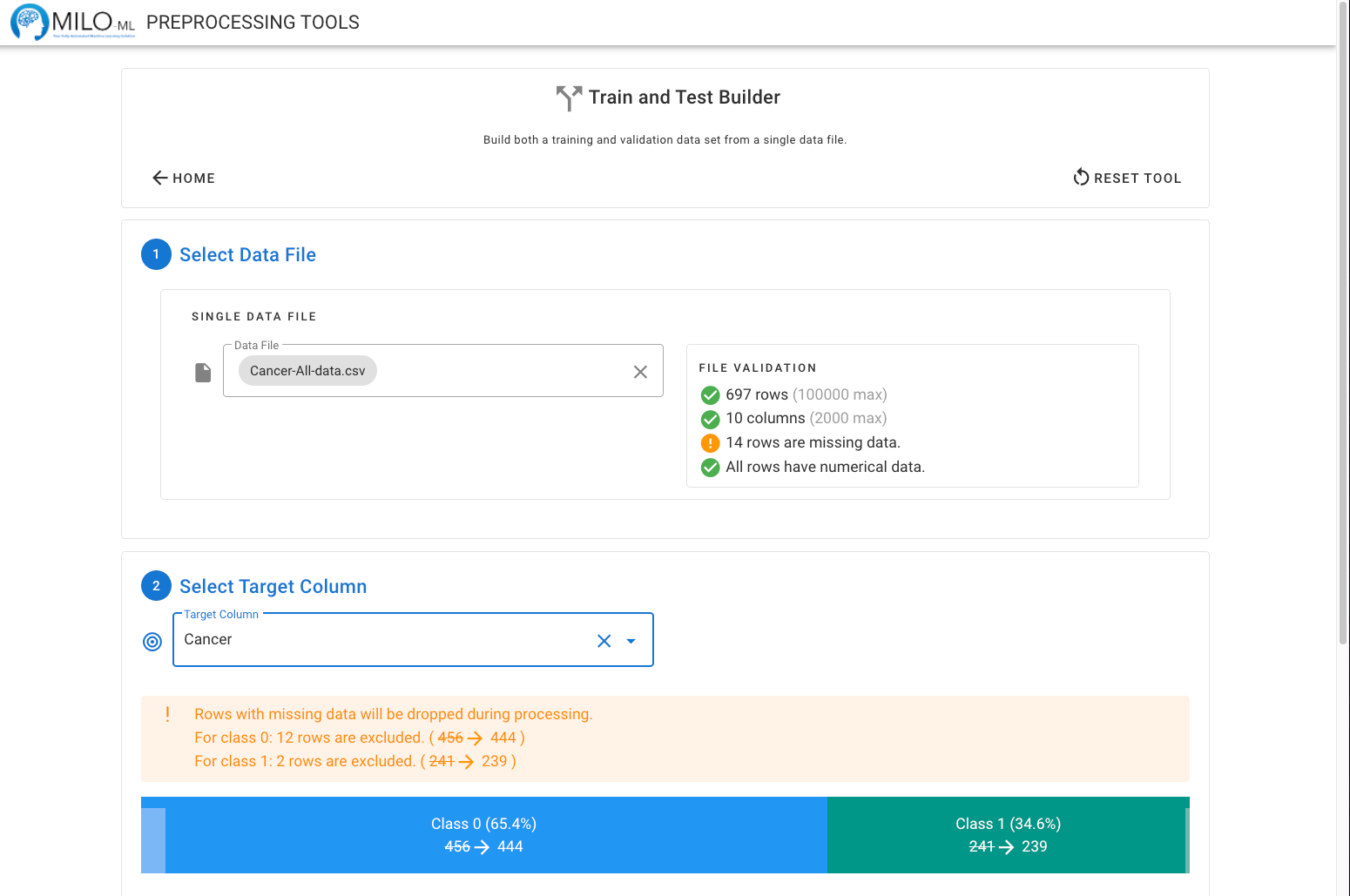
The amount of data placed in the training and generalization testing data files can then be adjusted. We recommend a minimum of 100 rows per class (total of 200) for the training data set. However this tool will allow you to build training sets as small as 50 rows (25 positives and 25 negative cases). Any missing data will also be reflected. The training data set automatically will sample equally between the two classes. This means that if the dataset is not perfectly balanced between the two classes, the majority class will have an increased prevalence in the generalized testing data set. If the goal is to maintain the original prevalence this option can be changed.
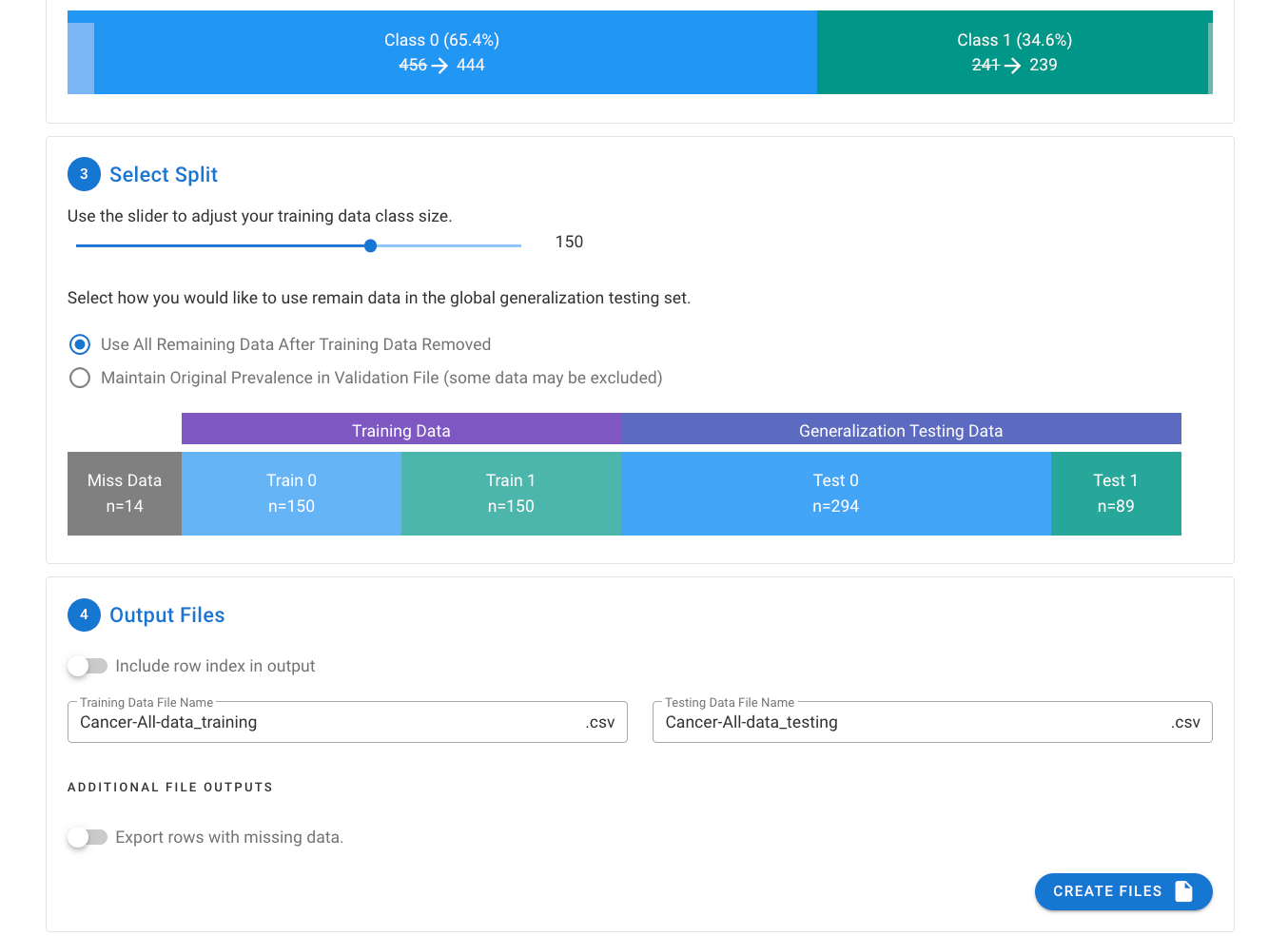
The below example shows the option to Maintain Original Prevalence with a subset of the majority class being excluded from the generalized testing data set.
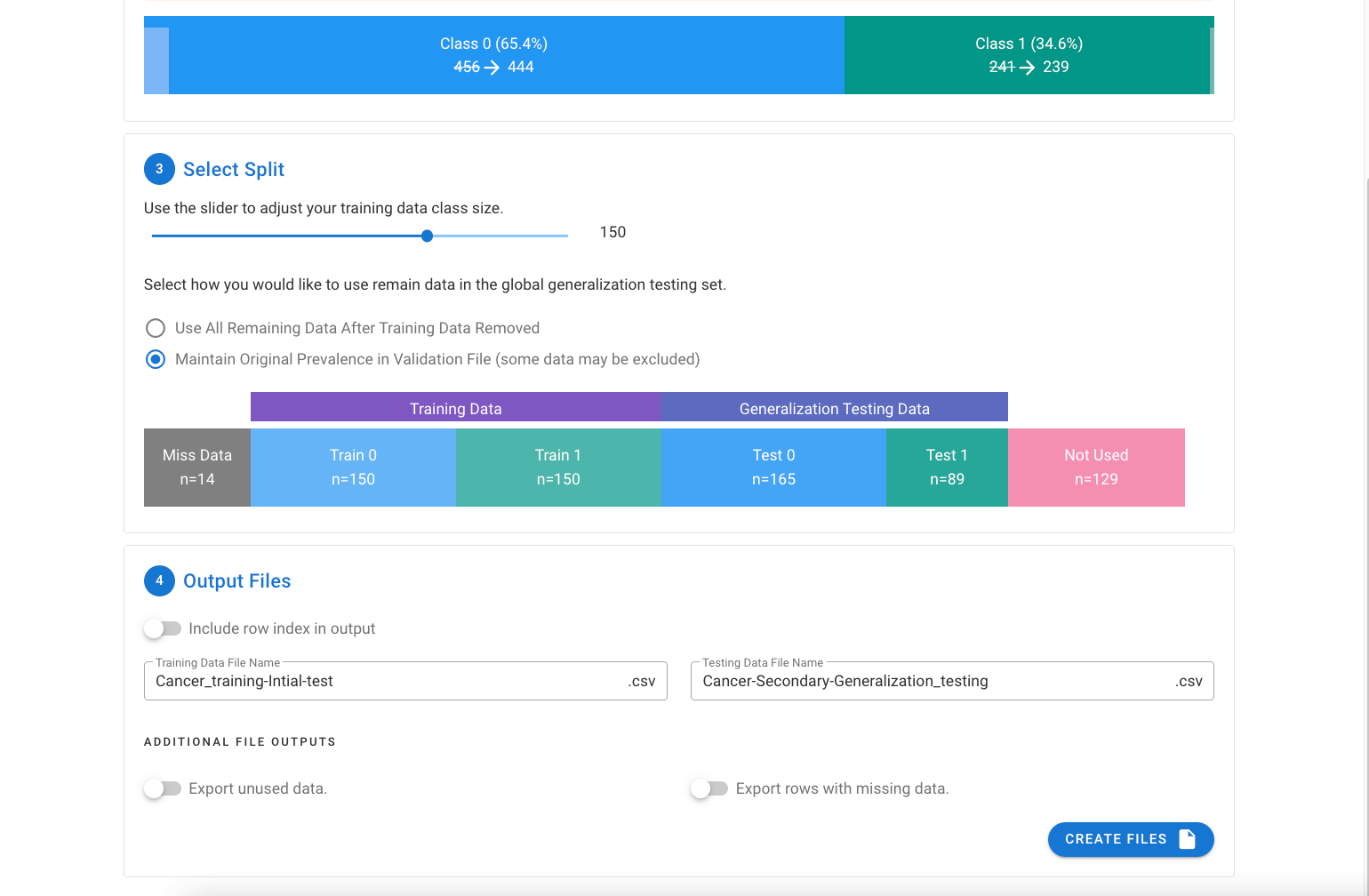
The final step provides the option to name the output files and if desired, export separate file(s) with the rows that were excluded if missing data, or if the prevalence was maintained (since equal numbers of the two classes will be taken for the original dataset to build the training data subset).
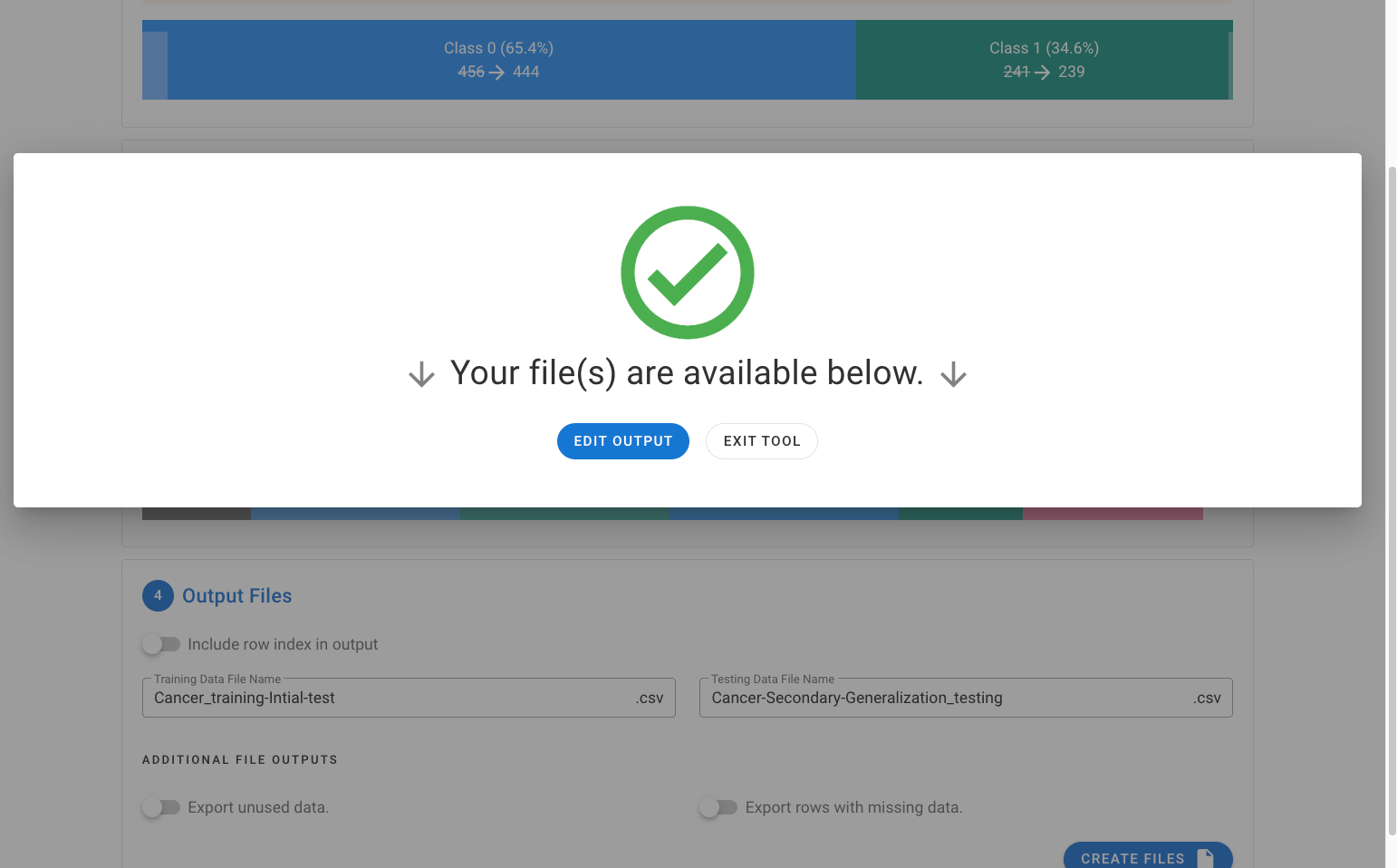
The files will be exported as a ZIP file and are now ready to be used within the MILO Auto-ML tool.